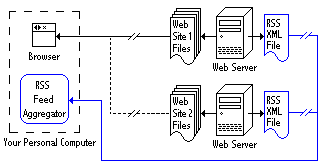
RSS is a method of distributing links to content in your web site that you'd like others to use. In other words, it's a mechanism to "syndicate" your content.
To understand syndication, consider the "real world" situation where artist Scott Adams draws a daily
Dilbert cartoon. The cartoon is made available to any newspaper that cares to run it, in exchange for a fee -- and 2,000 papers in 65 countries do so.
Unlike Scott Adams, syndication of web content via RSS is unlikely to make you rich. However, it can be an easy way to draw attention to your material, bringing you some traffic and perhaps a little net fame, depending on how good your information is.
What Is RSS?
How does RSS syndication work? Say you publish a new web page about a particular topic. You want others interested in that topic to know about it. By listing the page as an "item" in your RSS file, you can have the page appear in front of those who read information using RSS readers or "news aggregators" (explained more in my sidebar article,
RSS: Your Gateway To News & Blog Content). RSS also allows people to easily add links to your content within their own web pages. Bloggers are a huge core audience that especially does this.
What does RSS stand for? There's a can of worms. RSS as introduced by Netscape in 1999 then later abandoned in 2001 stood for "Rich Site Summary." Another version of RSS pioneered by
UserLand Software stands for "Really Simple Syndication." In yet another version, RSS stands for "RDF Site Summary."
History buffs might be interested that there's been some rivalry over who invented RSS. This is why we have both different names and indeed different "flavors" or versions of RSS. Mark Pilgrim's written an excellent article,
What Is RSS, that charts the different versions with recommendations on which to use. I'll also revisit the version choice you'll need to make. But first, let's look more closely at some basics of what goes into any RSS file.
How Easy Is RSS?
I've been exploring RSS because it was time that Search Engine Watch offered its own stories in this manner. I've read several tutorials about making a feed, and they generally suggest that it is easy. They often offer code that you can "cut-and-paste" and link over to specifications that I actually don't find that clear.
For example, the
RSS 2.0 specification has an "cloud" element that's optional but which a lay person might still wonder if they should use it. Meanwhile, heaven help the person who stumbles into the
RSS 1.0 specification and its complicated RDF syntax.
Sure, making an RSS file IS easy for many. If you understand HTML, you'll probably understand enough to do a cut-and-paste from someone else's RSS file to make your own file. Don't know HTML? Start a blog, because several blogging tools automatically generates RSS files.
As for those non-technical people using WYSIWYG page building tools or personal home page building systems, have faith. Even you can build an RSS file from scratch, as long as you dispense with some of the extra features you probably don't need. We'll go through how to do this below. Later, I'll also mention some
tools that will even do some or all of the work for you.
The RSS File
At the heart of an RSS file are "items." No matter what version of RSS you settle on, your file will have to include at least one item. Items are generally web pages that you'd like others to link to. For example, let's say you just created a web page reviewing a new cell phone that's being released. Information about that page would form an item.
To enter your item into the RSS file, you'll need three bits of information:
The title and description of your item need not match exactly the HTML title tag of the web page that the item refers to, nor the meta description tag, assuming you use these (don't know what they are? See my
How To Use HTML Tags article). You can write any title and description that you think will describe the page. However, using your page's title and meta description tag certainly makes it easy to copy and paste to build your RSS feed.
In the case of our example page, let's say this is the information we settle on to define it as an item:
Nokia 3650 Combines Phone And PhotosI've been playing with the new Nokia 3650. Finally, someone has got the combination of a cell phone with digital camera capabilities right!
http://allgadgetsreviewed.com/nokia3650.html
Now we have to surround that information with XML tags. These are similar to HTML tags, with the exception that unlike with HTML, there's no set definition of XML tags. Anyone can make up a particular XML tag. Whether it is useful depends on the program that reads the resulting XML file. In the case of RSS feeds, they have their own unique set of XML tags that are defined. Use these correctly, and then anything that reads RSS will understand your information.
Did that make your head spin? If so, don't reread -- just carry on to see how simple it is. First, open a text editor like Notepad. We're going to build our RSS file using it.
For your title, you need to start it with the <title> tag, then follow this with the text of the title, then end with the </title> tag. It looks like this:
<title>Nokia 3650 Combines Phone And Photos</title>
For your description, you do the same, starting out with the opening <description> tag, then following with the actual description, then "closing" with the </description> tag. Now you have this:
<title>Nokia 3650 Combines Phone And Photos</title>
<description>I've been playing with the new Nokia 3650. Finally, someone has got the combination of a cell phone with digital camera capabilities right!</description>
Next, we add the link information, beginning with <link>, following with the actual hyperlink, then closing with </link>. That gives us this:
<title>Nokia 3650 Combines Phone And Photos</title>
<description>I've been playing with the new Nokia 3650. Finally, someone has got the combination of a cell phone with digital camera capabilities right!</description>
<link>http://allgadgetsreviewed.com/nokia3650.html</link>
Now there's one more thing we need to do. We actually have to define all this information as forming a particular "item," which we do using a special item tag.
You place the opening item tag, <item> at the top or start of all the information we've listed. You then place the closing item tag, </item>, at the bottom or "end" of the item information. The finished product looks like this:
<item>
<title>Nokia 3650 Combines Phone And Photos</title>
<description>I've been playing with the new Nokia 3650. Finally, someone has got the combination of a cell phone with digital camera capabilities right!</description>
<link>http://allgadgetsreviewed.com/nokia3650.html</link>
</item>
Congratulations! You've now made your first item. There's a bit more to do to finish our RSS file. First, what if we have other items we want to syndicate? Then we simply add more item elements, just as we did above. You can have up to 15 items. New items tend to be inserted at the top, with old items removed from the bottom, to make room for new stuff.
With our example, let's see how things look if we add two more items:
<item>
<title>Nokia 3650 Combines Phone And Photos</title>
<description>I've been playing with the new Nokia 3650. Finally, someone has got the combination of a cell phone with digital camera capabilities right!</description>
<link>http://allgadgetsreviewed.com/nokia3650.html</link>
</item>
<item>
<title>Sanyo Tablet PC Amazes!</title>
<description>I was dubious about the new Tablet PCs, but then I saw the latest from Sanyo. Wow, cool looks and it works!</description>
<link>http://allgadgetsreviewed.com/sanyotablet.html</link>
</item>
<item>
<title>Canon MegaTiny Digital Camera Too Small</title>
<description>OK, there is a limit to just how small is too small. Canon's MetaTiny, no larger than a quarter, simply is too little to use properly</description>
<link>http://allgadgetsreviewed.com/metatiny.html</link>
</item>
Having defined items we want to distribute, we now have to define our site as a "channel." You'll use the same tags as with the items: title, description and link. However, this time the information will be about your entire site, rather than a particular page. That means our channel information would look like this:
<title>All Gadgets Reviewed</title>
<description>If it's a gadget, we review it. Learn what gadgets are hot and what's not!</description>
<link>http://allgadgetsreviewed.com</link>
Now, how does something reading our RSS file know that the information above is for our "channel" when it looks just like item information? Simple. As long as we don't surround this information with an opening and closing <item> tags, it won't be seen as item information but rather as channel information. That gives us this:
<title>All Gadgets Reviewed</title>
<description>If it's a gadget, we review it. Learn what gadgets are hot and what's not!</description>
<link>http://allgadgetsreviewed.com</link>
<item>
<title>Nokia 3650 Combines Phone And Photos</title>
<description>I've been playing with the new Nokia 3650. Finally, someone has got the combination of a cell phone with digital camera capabilities right!</description>
<link>http://allgadgetsreviewed.com/nokia3650.html</link>
</item>
<item>
<title>Sanyo Tablet PC Amazes!</title>
<description>I was dubious about the new Tablet PCs, but then I saw the latest from Sanyo. Wow, cool looks and it works!</description>
<link>http://allgadgetsreviewed.com/sanyotablet.html</link>
</item>
<item>
<title>Canon MegaTiny Digital Camera Too Small</title>
<description>OK, there is a limit to just how small is too small. Canon's MetaTiny, no larger than a quarter, simply is too little to use properly</description>
<link>http://allgadgetsreviewed.com/metatiny.html</link>
</item>
There are a few last things we need to do. First, we need to add a tag at the very top of the file saying that this is written according to the XML 1.0 specifications. Right under this, we also have to say what RSS version we are using.
So far, everything we've done is compatible with UserLand's popular RSS 0.91 version. However, it also matches UserLand's latest
RSS 2.0 version, as well, so we'll define the file as meeting that specification. This will allow us to add other neat features in the future, if we want.
Finally, after the RSS tag, we need to add an opening "channel" tag. That gives us this at the top of the file:
<?xml version="1.0"?>
<rss version="2.0">
<channel>
At the bottom of the file, after all the items we want to syndicate, we have to insert a closing channel and RSS tag, in that order. Those look like this:
</channel>
</rss>
This means our complete file looks like this:
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<title>All Gadgets Reviewed</title>
<description>If it's a gadget, we review it. Learn what gadgets are hot and what's not!</description>
<link>http://allgadgetsreviewed.com</link>
<item>
<title>Nokia 3650 Combines Phone And Photos</title>
<description>I've been playing with the new Nokia 3650. Finally, someone has got the combination of a cell phone with digital camera capabilities right!</description>
<link>http://allgadgetsreviewed.com/nokia3650.html</link>
</item>
<item>
<title>Sanyo Tablet PC Amazes!</title>
<description>I was dubious about the new Tablet PCs, but then I saw the latest from Sanyo. Wow, cool looks and it works!</description>
<link>http://allgadgetsreviewed.com/sanyotablet.html</link>
</item>
<item>
<title>Canon MegaTiny Digital Camera Too Small</title>
<description>OK, there is a limit to just how small is too small. Canon's MetaTiny, no larger than a quarter, simply is too little to use properly</description>
<link>http://allgadgetsreviewed.com/metatiny.html</link>
</item>
</channel>
</rss>
Mind Blowing Options
Everything shown above is the bare basics you need to create a file and start syndicating content from your web site. However, there are additional things you could do.
For example, rather than your entire web site being a "channel," you could actually have different content from within the web site be defined into separate channels. That's something I'm not going to explore in this article, but some of the
resources below will guide you through this, when you feel more comfortable.
As hinted at, RSS 2.0 allows you to insert all types of additional information into your feed. It can make your head spin to look at these and decide what to use. The easy answer is, don't bother with anything you don't know. Not every aggregator supports all the options offered. As long as you provide the minimum information suggested above, you should be fine.
Did I Choose The Right RSS Version?
Earlier, I'd mentioned there are different versions of RSS. Even though we entered the bare minimum of information, it turned out that we were able to have a file that was easily considered to be RSS 2.0, the latest version promoted by UserLand and which is widely used.
Indeed, the Syndic8 site
reports that the most popular format of RSS by far is RSS 0.91 -- and though we've used RSS 2.0, our file as shown is entirely compatible with RSS 0.91. In short, we're in safe company.
What about that RSS 1.0 version that I said was complicated. Well, it is complicated. However, some people might want to make use of some of the special capabilities that it offers. If you are interested in it, then check out the
official specification.
Saving The File
Now that we're done adding to the file, we need to save it. But what name shall we give it? I've looked and not seen any guidance on this. I imagine that's because as long as the file is valid (more below), it probably doesn't matter what it's called.
To make my own decision for Search Engine Watch, I decided to imitate what I saw out at UserLand, which promotes the RSS 2.0 standard that we used. UserLand's example feeds all ended .xml, so let's do the same. As for the first part, that really can be whatever you like. For our example, let's say we just call it feed.xml.
Now that our file is saved, we can place it anywhere we want on our web server. Let's say we put it in the root or home directory. Then the address to our RSS file would be:
http://allgadgetsreviewed.com/feed.xml
Validating The File
Now our RSS file is done, but did we do it right? To find out, we need to validate it. Use the aptly named
Feed Validator service. Simply enter the address to your RSS file, and you'll be told if everything is OK -- or if there's something wrong you need to fix.
How about a quick preview of how your new feed actually looks? Then pay a visit to
Wytheville Community College News Center. Again, enter your feed URL, and you'll see the clickable headlines and story descriptions nicely assembled inside a box.
The service will also generate a JavaScript code that you can post on your site. Anyone copying the JavaScript can automatically have your feed syndicated into their pages -- pretty neat!
Get Syndicated!
Now that your file is validated, you want the world to know about it! To make this happen, visit the RSS directories and search engines listed in the
RSS: Your Gateway To News & Blog Content article. They generally offer submission pages, where you can inform them of your feed.
You also want to make sure people who come to your web site see that you provide a feed. It's very common to post a link to the feed somewhere on the home page of a web site. If you have a dedicated news page, you may want to put it there, as well.
You can link to your feed with an ordinary HTML link. However, many sites use a small orange XML icon to link to the feed. I've also seen some sites use blue RSS icon. I could find no standard about using these. So, to be safe, I did all three with Search Engine Watch. Look on the
home page, and you'll see how it's done (and help yourself to the icons, if you need them).
Finally, it's good to "ping" one of the major services that track when web logs and RSS content changes. By doing this, you ensure that other sites that monitor these know to check back at your site for more content.
Weblogs.com is one of these major sites. Enter your site's name and the URL of your feed into the manual
Ping-Site Form, and it will know you've updated your feed. The
Specs page explains how to set up automatic notification.
blo.gs is another major change monitoring site. It is supposed to receive any changes that come from Weblogs.com, so you shouldn't need to notify it separately. However, if you want to be on the safe side, it's easily done. Use the
ping form, which also explains how to set up automatic pinging, as well.
RSS Headline Creator allows you to skip coding and manually choose the number of headlines you'd like to include in your file, up to the 15 maximum allowed. Then a form with boxes that you fill out will be made. Enter the right information, then push the "Make The Code" button. Your RSS file's code will be generated, for you to copy and paste into a text editor and save.
How To Get Your Web Site Content Syndicated is a Dec. 2002 tutorial by Kalena Jordan and Dan Thies from which I drew inspiration to get my own feed going.
Syndic8's How To Section lists a variety of tutorials that discuss how to build RSS files.
Content Syndication with RSS is a book by Ben Hammersley that was just released in March 2003. I haven't read it, but everything I've heard is that it should be excellent.
RSS Resources Directory from UserLand categorizes helpful information related to RSS, in different categories.



 When a search query is submitted to Google, it is routed to a data coop where monitors flash result pages at blazing speeds. When a relevant result is observed by one of the pigeons in the cluster, it strikes a rubber-coated steel bar with its beak, which assigns the page a PigeonRank value of one. For each peck, the PigeonRank increases. Those pages receiving the most pecks, are returned at the top of the user's results page with the other results displayed in pecking order.
When a search query is submitted to Google, it is routed to a data coop where monitors flash result pages at blazing speeds. When a relevant result is observed by one of the pigeons in the cluster, it strikes a rubber-coated steel bar with its beak, which assigns the page a PigeonRank value of one. For each peck, the PigeonRank increases. Those pages receiving the most pecks, are returned at the top of the user's results page with the other results displayed in pecking order.